[TOG/SiggraphAsia 2023] Commonsense Knowledge-Driven Joint Reasoning Approach for Object Retrieval in Virtual Reality
Abstract
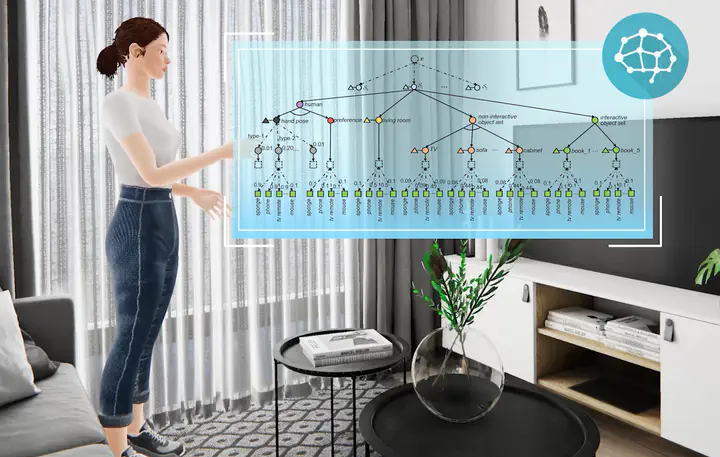
Retrieving out-of-reach objects is a crucial task in virtual reality (VR). One of the most commonly used approaches for this task is the gesture-based approach, which allows for bare-hand, eyes-free, and direct retrieval. However, previous work has primarily focused on assigned gesture design, neglecting the context. This can make it challenging to accurately retrieve an object from a large number of objects due to the one-to-one mapping metaphor, limitations of finger poses, and memory burdens. There is a general consensus that objects and contexts are related, which suggests that the object expected to be retrieved is related to the context, including the scene and the objects with which users interact. As such, we propose a commonsense knowledge-driven joint reasoning approach for object retrieval, where human grasping gestures and context are modeled using an And-Or graph (AOG). This approach enables users to accurately retrieve objects from a large number of candidate objects by using natural grasping gestures based on their experience of grasping physical objects. Experimental results demonstrate that our proposed approach improves retrieval accuracy. We also propose an object retrieval system based on the proposed approach. Two user studies show that our system enables efficient object retrieval in virtual environments (VEs).
Zhenliang Zhang
Research Scientist of AI
My research interests include wearable computing, machine learning, Cognitive Reasoning, and mixed/virtual reality.